
A History of Databases, Part 1: The Relational Database
From hierarchical hassles to the dominance of the relational database

All of the (justified) outrage by the SQL community over “AI hype” tweets like this made me wonder: how is the relational database, an invention from 1970, still dominating as a data model when data storage has changed so much? How much has it changed since its initial implementation? Did the world immediately realize how transformational the technology would become at the time? How did Oracle end up leading the space when they didn’t invent the technology?
These questions led me to investigate the surprisingly rich history of the R&D and deployment of the relational database.
I was going to write just one long post about mostly the relational database + a brief mention of modern databases (NoSQL, warehouse, lakes, etc.), but realized during the research that the history behind the latter is just as intriguing. I decided to split the post into two parts, with the first part focusing on the relational database from the 1960s to ~2000, and the second about the latter from 2000-present. Let’s get right into it:
Before the Relational Database
Charles Bachman at GE developed the first general-purpose database system, IDS, in the early 1960s. IBM soon followed in 1966 with the IMS, which was developed to keep track of purchase orders for Apollo mission. The former leveraged the network model while the latter used the hierarchical model.
The hierarchical model was the simpler of the two and, as the name suggests, stores all the data in a tree structure. Let’s say we’re the Apollo mission keeping track of our suppliers and the parts they’re supplying. The schema would look like this:

A few issues immediately stand out:
An instance must have one, and only one, parent, e.g. you can’t have a part that isn’t supplied by anybody, and a part cannot be supplied by more than one supplier
A symptom of the above is that there is a ton of replicated data, e.g. in the example above you have to store two rows for the same part, because two suppliers supply the same part
The network model helped with these issues by allowing more than one parent per instance (like a graph):


This was a bit more flexible than the hierarchical model, but queries quickly became extremely complex. For example, to figure out which part the supplier, “Squirrels”, supplies, you have to loop through the “Supplies” table until you find which row has Squirrels as a parent, store the child instance, loop through the “Supplied_By” table until you find a row whose child instance matches the stored child instance, and then return that parent.
More importantly, since the relationship between data defines its location in the database, application logic and physical storage were closely intertwined. This meant that if your database team decided to one day change the instances to be 60 bytes away from each other on disk instead of 50 (these kinds of changes would happen daily), you would have to rewrite a huge chunk of your application. Not fun.
The Birth of the Relational Database
In 1970, Ted Codd, a math PhD working for IBM Research, introduced the relational database in one of the most transformational papers in software history: A Relational Model of Data for Large Shared Data Banks. In the paper, he proposed a system that would:
Store the data in separate tables rather than as a large graph, and use relational algebra to figure out the relationships between locations in the database instead of inefficiently scanning the graph during each query. You would not need to duplicate a single piece of data, and new data categories could be added as separate tables without needing to completely rewrite the schema.
Access the data through some theoretical high-level language (this would later be standardized to SQL)
Abstract the physical implementation away from the application programmer. Even if the database’s internal representation switched from a hash map to a B-tree, the programmer wouldn’t have to change a single line as long as the schema stayed the same
TLDR: this approach made database systems infinitely more scalable.
The previous example with the suppliers and parts would look like this, which is what you’d expect it to look like today:

Although it’s obvious to us now that the relational model was wildly superior to anything before it, it got pushback in the database community, especially by an organization called CODASYL. They were actually led by Bachman and were trying to standardize the network data model + its corresponding query API in the early 70’s. They felt that Codd’s relational logic involved was too complicated (the world’s understanding of relational algebra was weaker back then) and that a high-level language wouldn’t be able to optimize queries as well as a programmer could (kind of like how people used to think that machines wouldn’t be able to compile code as well as humans).
Fortunately, as we know, these would become non-issues.
Initial Implementations
IBM wasn’t interested in pursuing this commercially, as IMS was already crushing it (it’s actually still around today, e.g. in some banks that haven’t migrated their database since the 70s). Fortunately, in 1972, some folks at IBM Research read the paper and sought out to implement the system, calling it System R. Interestingly, Codd wasn’t allowed to participate in the project at all, most likely because he was a mathematician and not a computer scientist.
I would say that the System R team pioneered ~70-80% of the relational database we know today. They created and implemented SQL, query optimization, table joins, two-phase locking, transaction management, the concept of ACID (minus the isolation), and much more.
The second group to fully implement Codd’s system was the INGRES group at UC Berkeley led by the legendary Michael Stonebraker and Eugene Wong, who were interested in proving the viability of the system after reading Codd’s paper.
Both systems would end up working well, but neither would be commercialized (yet). That honor would go to Larry Ellison, Bob Miner, and Ed Oates, who had just started a software consultancy firm when they stumbled upon a series of papers published by IBM’s System R team. Dumbfounded as to why no one had commercialized the technology yet, they immediately went to work.
Their first customer was the CIA, who wanted a functioning database in 2 years. They got it done in one and spent the following year productizing the software, publicly releasing the world's first commercial RDBMS in 1979. They named the product Oracle version 2 (there was no version 1), and subsequently changed the firm’s name to Oracle Systems.
The RDBMS Explosion
By the early 1980s, it was finally clear that the relational model was the winner. Realizing that they dropped the ball in failing to commercialize System R, IBM quickly released SQL/DS in 1981, and then the much more popular DB2 in 1983. As the largest tech company at the time, they were able to push ANSI to standardize SQL, which benefited Oracle but essentially killed off Ingres, who had commercialized at this point but was using a query language called QUEL. Stonebraker would soon go back to Berkeley and start Ingres’s successor, Postgres (yes, THAT Postgres).
A few other competitors popped up throughout the next decade, the most formidable one by far being Microsoft SQL Server, but Oracle became the clear winner in the market with IBM coming at a distant 2nd.
How did Oracle crush IBM even though they only had a two-year head start? This isn’t talked about much since DB2 was still able to make billions of dollars of revenue within a decade. There’s no clear answer, but my guess is a combination of Oracle’s insane execution + IBM’s focus on the dying mainframe market.
Open-source databases joined the party in the late 1990’s/early 2000’s when MySQL was released in 1995 (officially open-sourced in 2000) and Postgres migrated from QUEL to SQL the same year, meaning people actually started using it. These two came at the perfect time, as the explosion of the Internet meant that the average application developer, not just the Fortune 500, would now need a robust database system.
As we know now, both would become leaders in the market. The 2023 market share rankings are below:
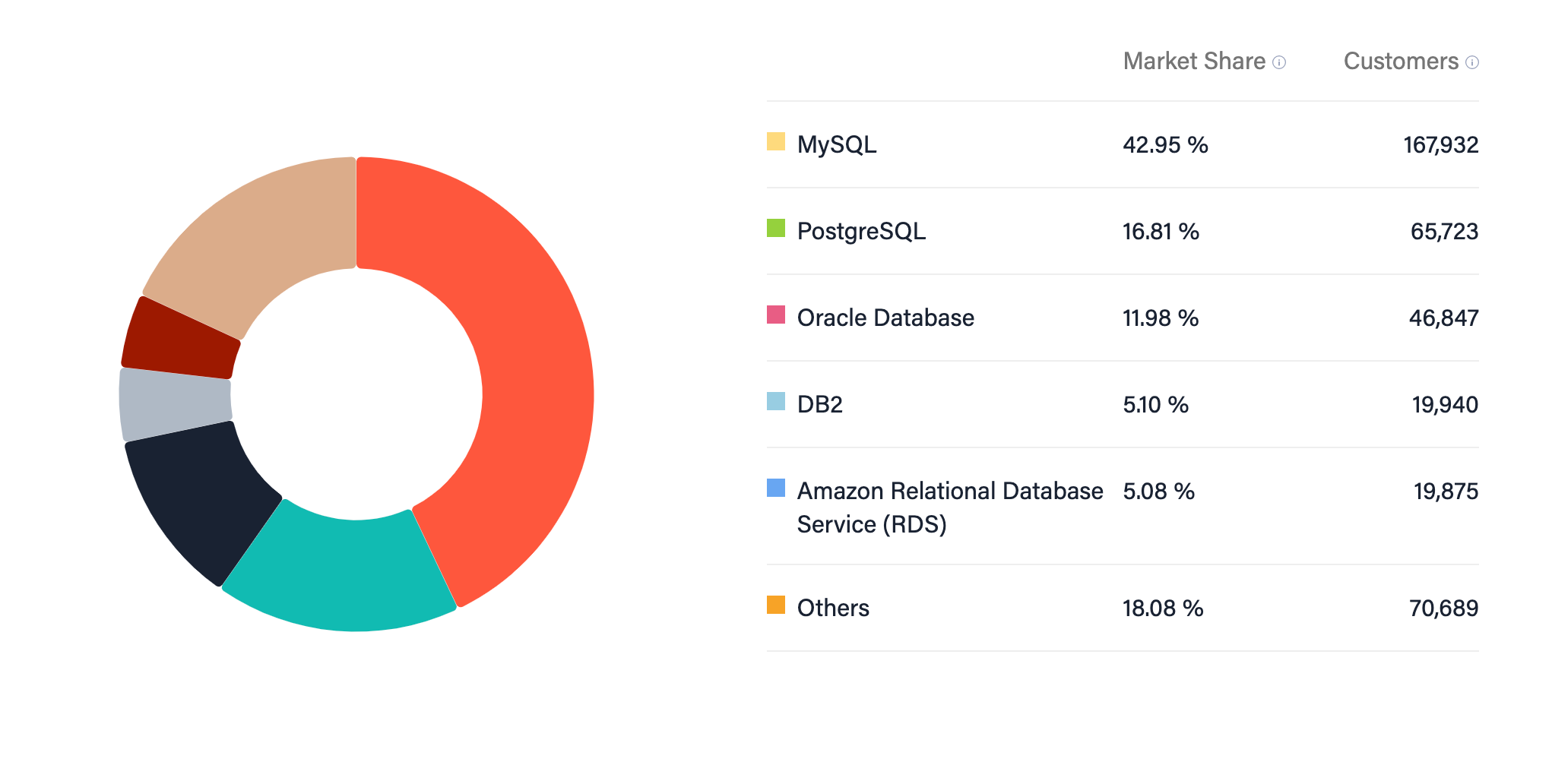
As a post-2010 developer, I was surprised by how much higher MySQL is than Postgres, since the latter is more popular nowadays. After going down a rabbit hole of old Reddit threads, the consensus seems to be that although Postgres has always been more powerful, MySQL used to be significantly easier to boot up and use. Postgres eventually caught up on the ease of use but MySQL never became more powerful, especially after the Sun/Oracle acquisitions. Let me know if this is incorrect or if you have other potential reasons!
RDBMS is Still King
This might be cheating since we haven’t covered the other data models yet, but I wanted to come back to the original question of why no one has been able to supplant the relational database, given that the vast majority of the technical innovation was made in the 70’s and 80’s. It boils down to a few things:
Data Integrity due to ACID: The principles of atomicity, consistency, and durability were introduced by Jim Gray of the System R team in 1981, and isolation was introduced by Andreas Reuter and Theo Harder in their 1983 paper. As we'll see in part 2, every data model that attempts to rival the RDBMS ends up compromising on ACID, making it a non-starter for companies dealing with high read+write volume in critical applications.
SQL Standardization: The other common drawback of other data models is a lack of standardization, meaning that developers and analysts have to learn whole new languages and standards between different database systems. SQL has its issues (many argue that QUEL was the superior language), but its standardization has been key in solidifying the RDBMS as the industry norm.
That’s it for part 1! Part 2 will be focused on 2000 to the present, covering NoSQL, MapReduce, warehouses, distributed SQL, and more.
Fascinating history. By the way, the colors on the chart are not corresponding to the ones in the legend